MiniMax-2.5 (229B MoE) Expert Offload and Web Generation: IQ5_K to IQ3_S
Complete record of running the 229B MoE model MiniMax-2.5 on EPYC 9175F + RTX PRO 6000. Expert Offload benchmarks across three quantization levels (IQ5_K/IQ4_NL/IQ3_S), plus one-shot web generation tests: React LP and dental clinic static site. Configuration, benchmark data, and speed-quality trade-offs for fitting a 157GB model on 96GB VRAM.

Summary
MiniMax-2.5 (229B MoE, 8 active out of 256 experts) runs stably on 96GB VRAM via Expert Offload (-ot exps=CPU).
Decode speed holds at 34-37 tok/s (IQ5_K), and dropping to IQ3_S allows more weights on GPU for improved speed. Using this inference capability, two one-shot web generation tests were validated: a React landing page (IQ4_NL) and a dental clinic static site (IQ3_S).
Test Environment
| Item | Specification |
|---|---|
| CPU | AMD EPYC 9175F (Zen 5, 16C/32T, L3 512MB) |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q (96GB VRAM) |
| Memory | DDR5-6400 768GB (12ch) |
| OS | Ubuntu 24.04 LTS |
| Runtime | ik_llama.cpp (build 4192) |
| Container | Podman rootless |
Model Specifications
| Item | Value |
|---|---|
| Architecture | MiniMax-M2 (MoE) |
| Size | 229B.A10B (229B total, 10B active) |
| Layers | 62 |
| Experts | 256 (8 active) |
| Training context | 196,608 |
| rope freq_base | 5,000,000 |
Part 1: Expert Offload Benchmark (IQ5_K)
Execution Command
podman run --rm -it \
--device nvidia.com/gpu=all \
-p 8081:8080 \
--shm-size 16g \
--cap-add=SYS_NICE \
-v "$MO":/models:ro,Z \
$IMG \
--host 0.0.0.0 --port 8080 \
-m "$MODEL" \
--no-mmap --jinja \
-c 65536 \
--threads 13 --threads-batch 25 \
-b 2048 -ub 2048 \
-ngl 99 \
-ot exps=CPU \
-ctk f16 -ctv f16 \
--warmup-batch \
-fa on
Key parameters:
-ot exps=CPU: Force Expert weights (bulk of 157GB) to CPU memory-ngl 99: Shows 63/63 layers GPU-offloaded, but Experts override via-ot--no-mmap: Pin 157GB in physical RAM, eliminate page faults--warmup-batch: Run warmup on startup
Memory Layout
| Region | Size | Location |
|---|---|---|
| CPU buffer (Expert weights) | 157,356 MiB (~154GB) | CPU RAM |
| KV cache | 15,872 MiB (~15.5GB) | CUDA0 |
| Compute buffer | 1,990 MiB | CUDA0 |
| GPU buffer (Attention, etc.) | 3,579 MiB | CUDA0 |
Actual GPU VRAM usage is ~21GB. The remaining 75GB is available for KV cache expansion.
Results: 8 Consecutive Runs (65K Context)
| Run | Prompt(tok) | PP(tok/s) | Gen(tok) | TG(tok/s) | Total(s) |
|---|---|---|---|---|---|
| 1 | 753 | 214.07 | 215 | 35.37 | 9.6 |
| 2 | 386 | 170.36 | 196 | 35.23 | 7.8 |
| 3 | 297 | 161.38 | 240 | 35.21 | 8.7 |
| 4 | 341 | 166.12 | 783 | 34.57 | 24.7 |
| 5 | 1,264 | 205.46 | 734 | 34.53 | 27.4 |
| 6 | 942 | 215.21 | 921 | 34.30 | 31.2 |
| 7 | 938 | 216.23 | 157 | 34.31 | 8.9 |
| 8 | 1,075 | 176.32 | 1,351 | 33.76 | 46.1 |
| Metric | PP(tok/s) | TG(tok/s) |
|---|---|---|
| Mean | 190.64 | 34.66 |
| Median | 190.89 | 34.55 |
| Min | 161.38 | 33.76 |
| Max | 216.23 | 35.37 |
Extended Session (131K Context)
| # | PP(tok) | TG(tok) | Ctx Used | PP(tok/s) | TG(tok/s) |
|---|---|---|---|---|---|
| 1 | 3,227 | 72 | 4,820 | 268.08 | 37.69 |
| 4 | 2,708 | 512 | 8,223 | 289.89 | 35.96 |
| 8 | 1,965 | 192 | 11,172 | 313.60 | 35.39 |
TG speed is extremely stable at 33.7-37.7 tok/s. No sharp degradation as context accumulates.
Analysis: Expert Offload Practicality
- Speed stability: ~10% TG variation across 8 runs. PCIe bandwidth is the bottleneck but provides consistent rate-limiting
- “All layers GPU offloaded” trap: Logs show “offloaded 63/63 layers to GPU” but Expert weights are actually on CPU via
-ot. Display versus reality diverge - Prompt cache: 6,029 tokens → 1,460 MiB state, 23,104 tokens → 5,596 MiB. TTFT reduction confirmed on repeated runs
- Tokenizer warning:
special_eos_id is not in special_eog_ids— if left unaddressed, EOG/EOS judgment becomes unstable
One-Prompt Generation Live Demonstration
To verify the output quality of one-prompt generation, we recorded MiniMax-2.5 generating a website in real time. By observing the inference server output directly, you can confirm the actual generation quality.
This video demonstrates:
- One-shot code generation process from a specification document (AGENTS.md)
- Token-by-token generation phase output speed
- Structure and quality of the generated code
Part 2: React LP One-Shot Generation (IQ4_NL)
Configuration
- Quantization: IQ4_NL (lighter than IQ5_K, quality nearly maintained)
- Context: 262,144 (256K)
- Input:
AGENTS.md(detailed site specification for loFT LLC) - Stack: Vite + React + TypeScript + Tailwind CSS v4
Results
MiniMax-2.5 generated a complete loFT LLC corporate site from the AGENTS.md specification in one shot.
Generated component structure (Atomic Design):
- Atoms: Button, Heading, Text, Icon, Input, TextArea, Badge
- Molecules: ServiceCard, CaseStudyCard, TestimonialCard, NavItem
- Organisms: NavBar, HeroSection, ServiceGrid, ProcessTimeline, ContactForm, Footer
Implemented features:
- Hero section (animated background with function curves)
- Contact form (
react-hook-form+zodvalidation) - SEO optimization (JSON-LD structured data, dynamic meta tags, favicon generation)
- SPA routing (
react-router-dom)
Notable: Autonomous Tailwind v4 adaptation
Tailwind CSS v4 deprecated tailwind.config.js in favor of CSS-first configuration. MiniMax-2.5 noticed this from npx tailwindcss init failure logs and switched to @import "tailwindcss";.
TypeScript error handling: The model read build error output, attempted to identify and fix type import mismatches and unused variables, ultimately reaching “Build Succeeded.”
Part 3: Dental Clinic Static Site (IQ3_S GPU Full Load)
Design Intent: Why IQ3_S
Dropping to IQ3_S allows placing more Expert weights in GPU VRAM, reducing latency from -ot exps=CPU. Precision is partially traded, but the speed gain is net-positive for structured code generation tasks.
Requirements
- 6-page static HTML site (index, services, doctors, info, visit, access)
- No build step, Tailwind CSS (CDN), Alpine.js (CDN)
Results: 6 Pages in ~18 Minutes
| Page | Key Content | Alpine.js Interactions |
|---|---|---|
| index.html | Hero, 8 service cards, doctor previews, news | Mobile nav, language switch UI |
| services.html | 14 treatment cards, FAQ section | Category filtering, accordion |
| doctors.html | 6 doctor profiles, specialties | Expandable details |
| info.html | Fee table, insurance, payment methods | Estimate modal |
| visit.html | First visit flow, reservations | Validated form |
| access.html | Map, transit, parking | Direction tab switching |
- Total time: 18 minutes 2 seconds (design, implementation, diagnostics)
- Diagnostics: Zero errors and warnings
- Quality: Even at IQ3_S, accessibility (ESC key close, focus management) and semantic HTML structure were maintained
Generated Site Screenshots
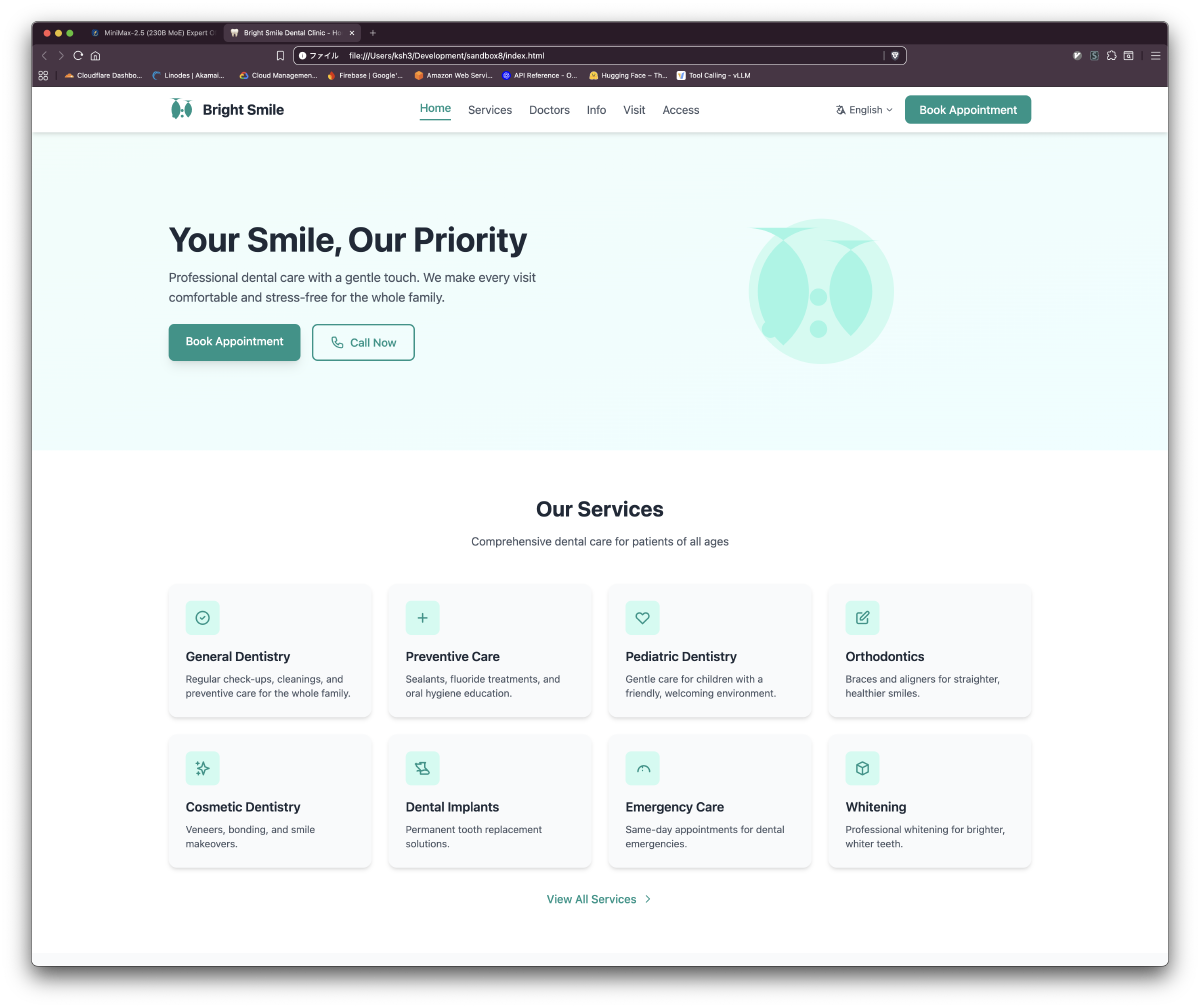
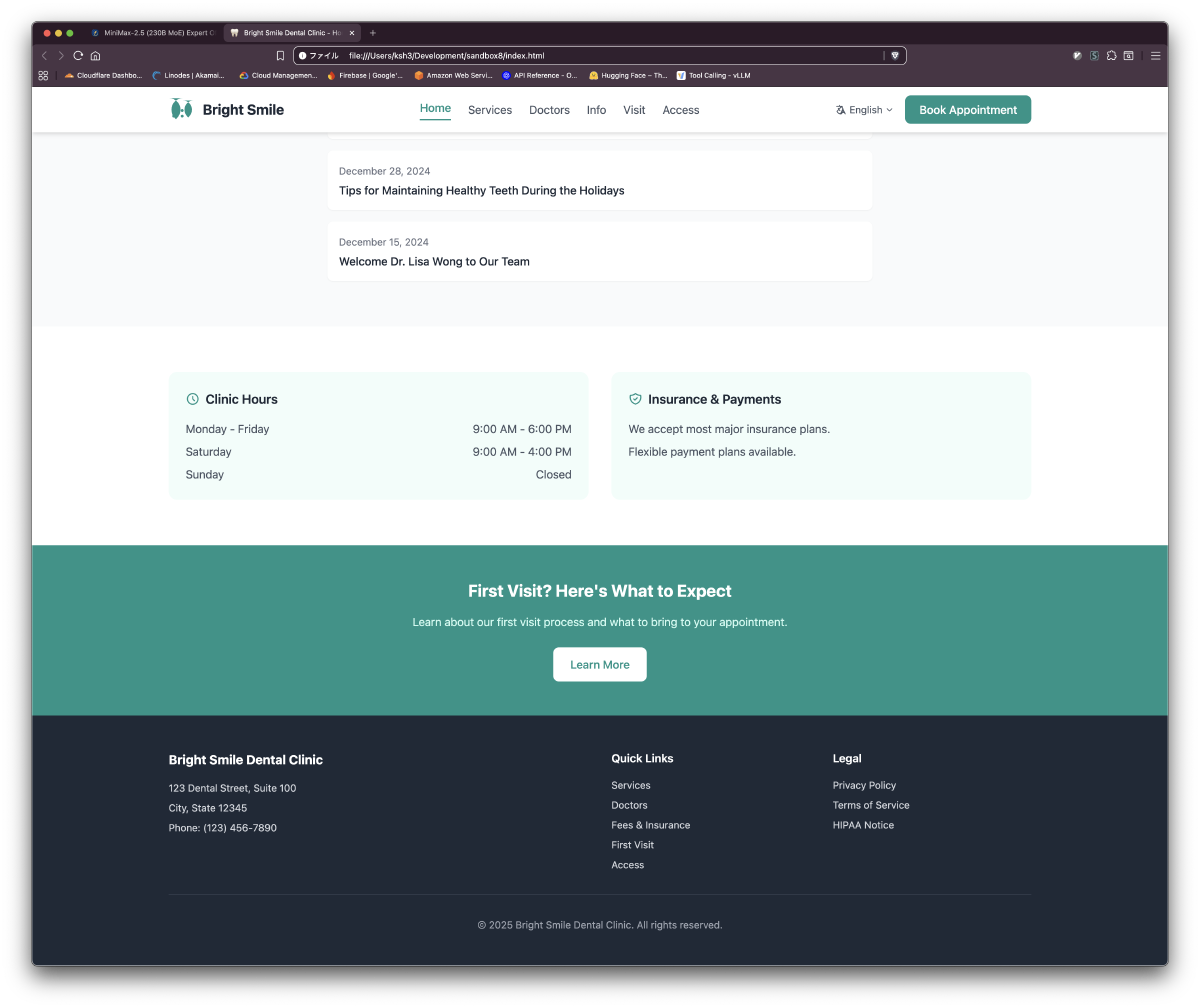
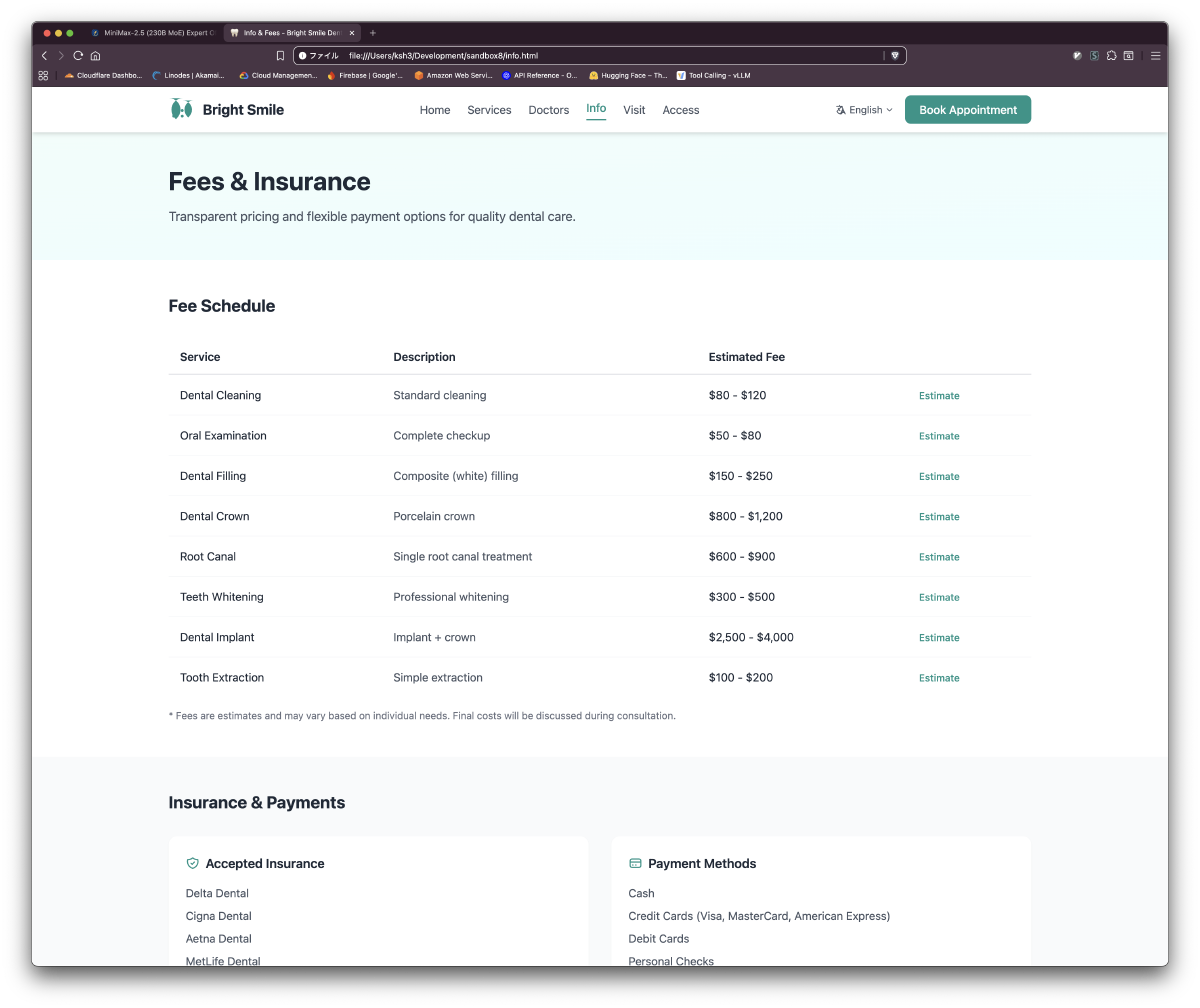
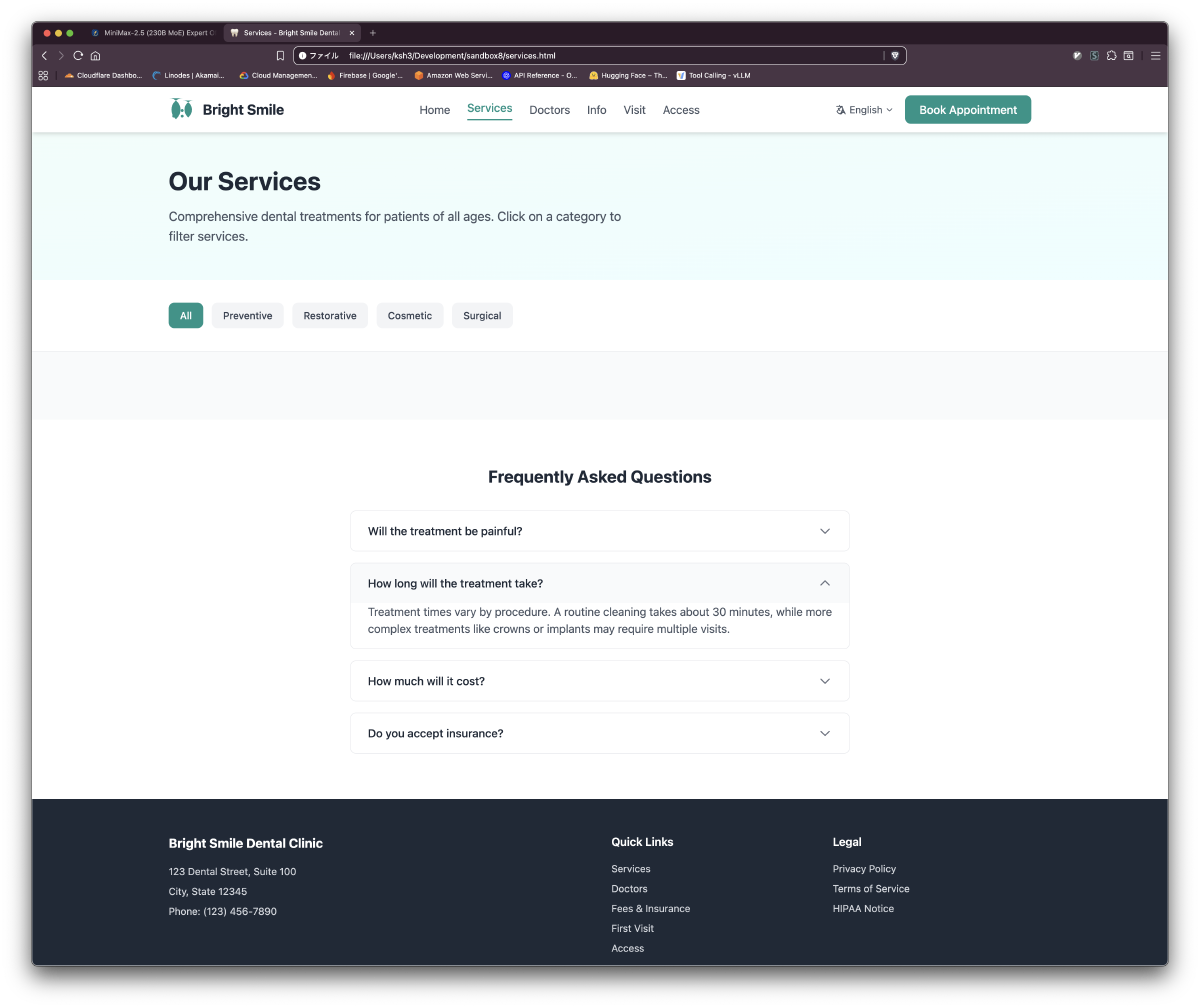
Quantization-Level Operating Guidelines
| Quantization | Model Size | TG Speed | Use Case |
|---|---|---|---|
| IQ5_K | 157.7 GiB | 34-37 tok/s | Benchmarking, quality-critical generation |
| IQ4_NL | ~120 GiB (est.) | Improved | Long-context work, React LP generation |
| IQ3_S | ~100 GiB (est.) | Further improved | High-volume structured code, speed-priority |
“Running the biggest model at max precision” is not always optimal. Adjusting quantization to task characteristics and prioritizing GPU-resident weights is a practical operational strategy.
Takeaways
A 229B model running locally at 37 tok/s would have been hard to imagine a few years ago. Expert Offload — “if it doesn’t fit on GPU, move it to CPU” — is a rational approach exploiting MoE’s structural property of independent experts. Both the React LP and dental clinic site produced production-grade code from specifications. The 229B-class model’s judgment capacity demonstrably maintains cross-file consistency on complex tasks.
Reproduction
Model Download
huggingface-cli download <quantizer>/MiniMax-M2.5-GGUF \
--include "MiniMax-M2.5-IQ5_K.gguf" \
--local-dir /mnt/data/hf/hub/models--MiniMax-2.5-GGUF
Benchmark
Refer to the “Part 1: Execution Command” section above. Requires ik_llama.cpp with Expert Offload support.
Measurement
curl -s http://localhost:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"minimax","messages":[{"role":"user","content":"Explain MoE architecture"}],"max_tokens":512}'
Technical Notes
–no-mmap Necessity
Reading 157GB via mmap causes intermittent page faults that destabilize latency. --no-mmap pins to physical RAM, eliminating page faults during inference. Startup time increases to several minutes.
Expert Count vs Decode Speed
MiniMax-2.5 selects 8 from 256 experts. Compared to GLM-4.7-Flash (4 from 64), Expert selection compute is larger but individual Expert size is smaller (FFN 1,536 dim). Expert count alone does not predict Decode speed.