MiniMax-2.5 (229B MoE) Expert Offload 運用と Web 生成検証:IQ5_K から IQ3_S まで
229B級MoEモデル MiniMax-2.5 を EPYC 9175F + RTX PRO 6000 環境で動かした全記録。IQ5_K/IQ4_NL/IQ3_S の3段階の量子化で Expert Offload ベンチマークを実施し、React LP と歯科医院静的サイトのワンショット生成を検証した。157GB のモデルを 96GB VRAM で回すための設定と、量子化レベルごとの速度・品質トレードオフの実測データ。

結論
MiniMax-2.5(229B MoE, 256エキスパート中8活性)は、Expert Offload(-ot exps=CPU)により96GB VRAMで安定動作する。
Decode速度は量子化レベルに依存して34〜37 tok/s(IQ5_K)を維持し、IQ3_Sまで下げるとGPU側にさらに重みを寄せて速度を改善できる。この推論性能を活かし、React LP(IQ4_NL)と歯科医院静的サイト(IQ3_S)の2つのワンショット Web 生成を検証した。
実験環境
| 項目 | 仕様 |
|---|---|
| CPU | AMD EPYC 9175F(Zen 5, 16C/32T, L3 512MB) |
| GPU | NVIDIA RTX PRO 6000 Blackwell Max-Q(96GB VRAM) |
| メモリ | DDR5-6400 768GB(12ch) |
| OS | Ubuntu 24.04 LTS |
| Runtime | ik_llama.cpp(build 4192) |
| Container | Podman rootless |
モデル仕様
| 項目 | 値 |
|---|---|
| アーキテクチャ | MiniMax-M2(MoE) |
| サイズ | 229B.A10B(総229B、活性10B) |
| レイヤー数 | 62 |
| エキスパート数 | 256(活性8) |
| 学習コンテキスト長 | 196,608 |
| rope freq_base | 5,000,000 |
Part 1: Expert Offload ベンチマーク(IQ5_K)
実行コマンド
podman run --rm -it \
--device nvidia.com/gpu=all \
-p 8081:8080 \
--shm-size 16g \
--cap-add=SYS_NICE \
-v "$MO":/models:ro,Z \
$IMG \
--host 0.0.0.0 --port 8080 \
-m "$MODEL" \
--no-mmap --jinja \
-c 65536 \
--threads 13 --threads-batch 25 \
-b 2048 -ub 2048 \
-ngl 99 \
-ot exps=CPU \
-ctk f16 -ctv f16 \
--warmup-batch \
-fa on
パラメータの意図:
-ot exps=CPU: Expert重み(157GB中の大部分)をCPUメモリに強制配置-ngl 99: 全63レイヤーをGPUオフロード表示にするが、Expertは-otで上書き--no-mmap: 157GBを実メモリに確保し、ページフォールトを排除--warmup-batch: 起動時ウォームアップ実行
メモリ配置
| 領域 | サイズ | 配置先 |
|---|---|---|
| CPU buffer(Expert重み) | 157,356 MiB(約154GB) | CPU RAM |
| KV cache | 15,872 MiB(約15.5GB) | CUDA0 |
| Compute buffer | 1,990 MiB | CUDA0 |
| GPU buffer(Attention等) | 3,579 MiB | CUDA0 |
GPU VRAMの実使用量は約21GB。残り75GBはKVキャッシュ拡張に使える。
結果: 8連続ラン(65Kコンテキスト設定)
| Run | Prompt(tok) | PP速度(tok/s) | Gen(tok) | TG速度(tok/s) | 合計(s) |
|---|---|---|---|---|---|
| 1 | 753 | 214.07 | 215 | 35.37 | 9.6 |
| 2 | 386 | 170.36 | 196 | 35.23 | 7.8 |
| 3 | 297 | 161.38 | 240 | 35.21 | 8.7 |
| 4 | 341 | 166.12 | 783 | 34.57 | 24.7 |
| 5 | 1,264 | 205.46 | 734 | 34.53 | 27.4 |
| 6 | 942 | 215.21 | 921 | 34.30 | 31.2 |
| 7 | 938 | 216.23 | 157 | 34.31 | 8.9 |
| 8 | 1,075 | 176.32 | 1,351 | 33.76 | 46.1 |
| 指標 | PP速度(tok/s) | TG速度(tok/s) |
|---|---|---|
| 平均 | 190.64 | 34.66 |
| 中央値 | 190.89 | 34.55 |
| 最小 | 161.38 | 33.76 |
| 最大 | 216.23 | 35.37 |
別セッション(131Kコンテキスト設定時)
| # | PP(tok) | TG(tok) | Ctx使用 | PP速度(tok/s) | TG速度(tok/s) |
|---|---|---|---|---|---|
| 1 | 3,227 | 72 | 4,820 | 268.08 | 37.69 |
| 4 | 2,708 | 512 | 8,223 | 289.89 | 35.96 |
| 8 | 1,965 | 192 | 11,172 | 313.60 | 35.39 |
TG速度は33.7〜37.7 tok/sで極めて安定。コンテキスト蓄積による急激な速度低下は観測されなかった。
考察: Expert Offloadの実用性
- 速度の安定性: 8ラン通じてTG変動幅約10%。PCIe帯域がボトルネックだが一定速度で律速されるため安定
- 「全層GPU offload」表示のトラップ: ログ上「offloaded 63/63 layers to GPU」と出るが、Expert重みは
-otでCPU配置。表示と実態が乖離する - プロンプトキャッシュ: 6,029トークン保存で1,460 MiB、23,104トークンで5,596 MiB。反復実行でTTFT短縮効果を確認
- tokenizer警告:
special_eos_id is not in special_eog_idsを放置するとEOG判定が不安定になるリスクあり
ワンプロンプト生成の実演動画
ワンプロンプトでの生成内容を確認するため、MiniMax-2.5によるWebサイト生成の実行風景を撮影しました。推論サーバーの出力をリアルタイムで観察することで、実際の生成品質を確認できます。
この動画では以下を確認できます:
- 仕様書(AGENTS.md)からのワンショットコード生成プロセス
- Token-by-tokenの生成フェーズの出力速度
- 生成されたコードの構造と品質
Part 2: React LP ワンショット生成(IQ4_NL)
実行構成
- 量子化: IQ4_NL(IQ5_Kより軽量、品質はほぼ維持)
- コンテキスト: 262,144(256K)
- 入力:
AGENTS.md(loFT LLC の詳細なサイト仕様書) - スタック: Vite + React + TypeScript + Tailwind CSS v4
検証結果
MiniMax-2.5は、AGENTS.mdの仕様書からloFT LLCコーポレートサイトをワンショットで生成した。
生成されたコンポーネント構成(Atomic Design):
- Atoms: Button, Heading, Text, Icon, Input, TextArea, Badge
- Molecules: ServiceCard, CaseStudyCard, TestimonialCard, NavItem
- Organisms: NavBar, HeroSection, ServiceGrid, ProcessTimeline, ContactForm, Footer
実装された機能:
- ヒーローセクション(アニメーション背景+関数曲線)
- コンタクトフォーム(
react-hook-form+zodバリデーション) - SEO最適化(JSON-LD構造化データ、動的メタタグ、favicon自動生成)
- SPAルーティング(
react-router-dom)
注目点: Tailwind v4への自律適応
Tailwind CSS v4ではtailwind.config.jsが廃止されCSS-firstに移行した。MiniMax-2.5はnpx tailwindcss initの失敗ログからこの変化に気づき、@import "tailwindcss";への自律的な修正を実行。
TypeScript型エラーへの対応: ビルドエラー出力を読み取り、型インポートのミスや未使用変数を特定・修正を試み、最終的に「Build Succeeded」に到達した。
IQ4_NLでの運用判断
IQ5_K(157GB)からIQ4_NL(約120GB想定)に落とすことで、PCIe転送量が減少しDecode速度の改善が期待できる。本検証では54,000トークン超のコンテキストでもLCP similarity(プロンプトキャッシュ)が機能し、反復デバッグが効率的に進行した。
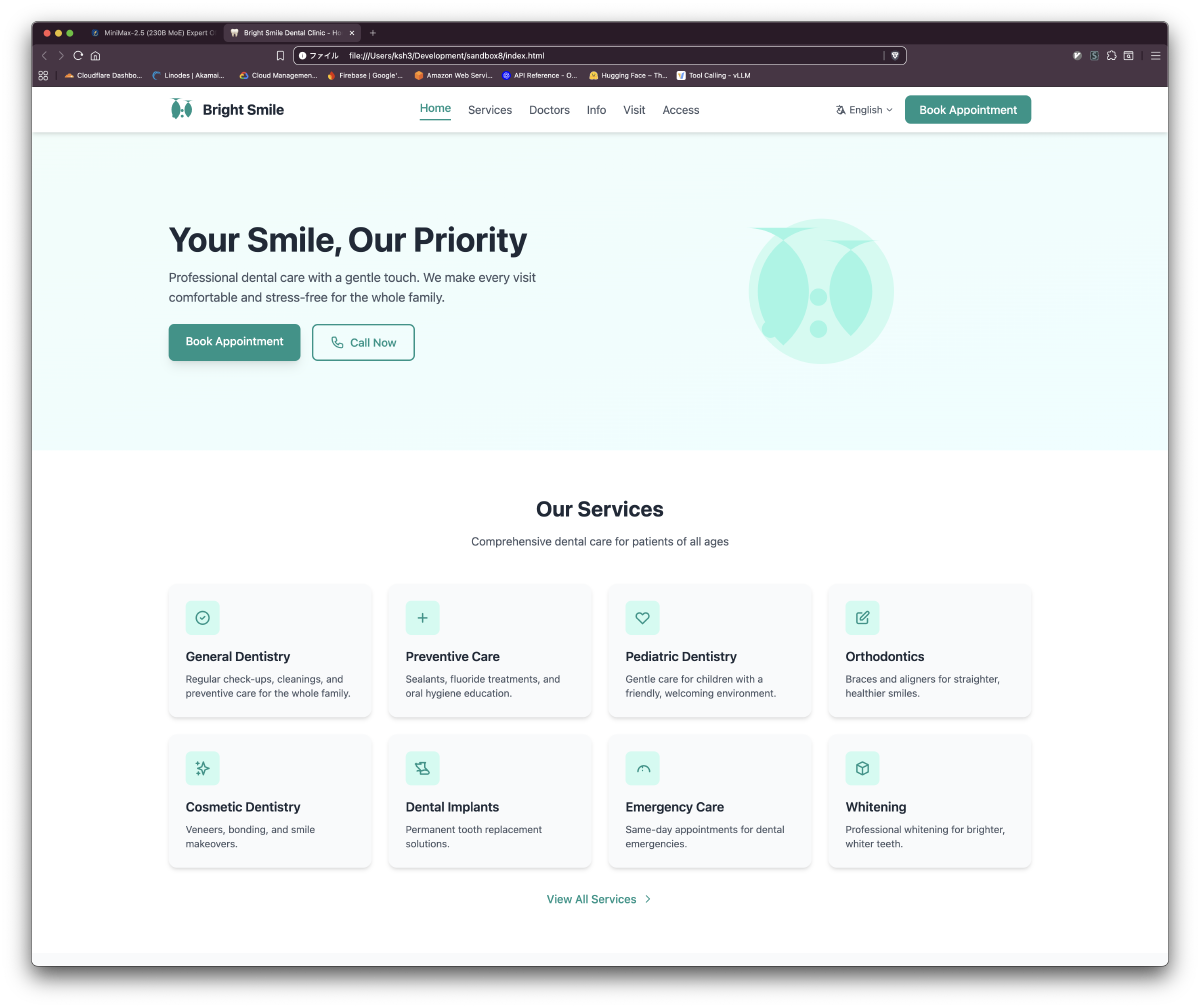
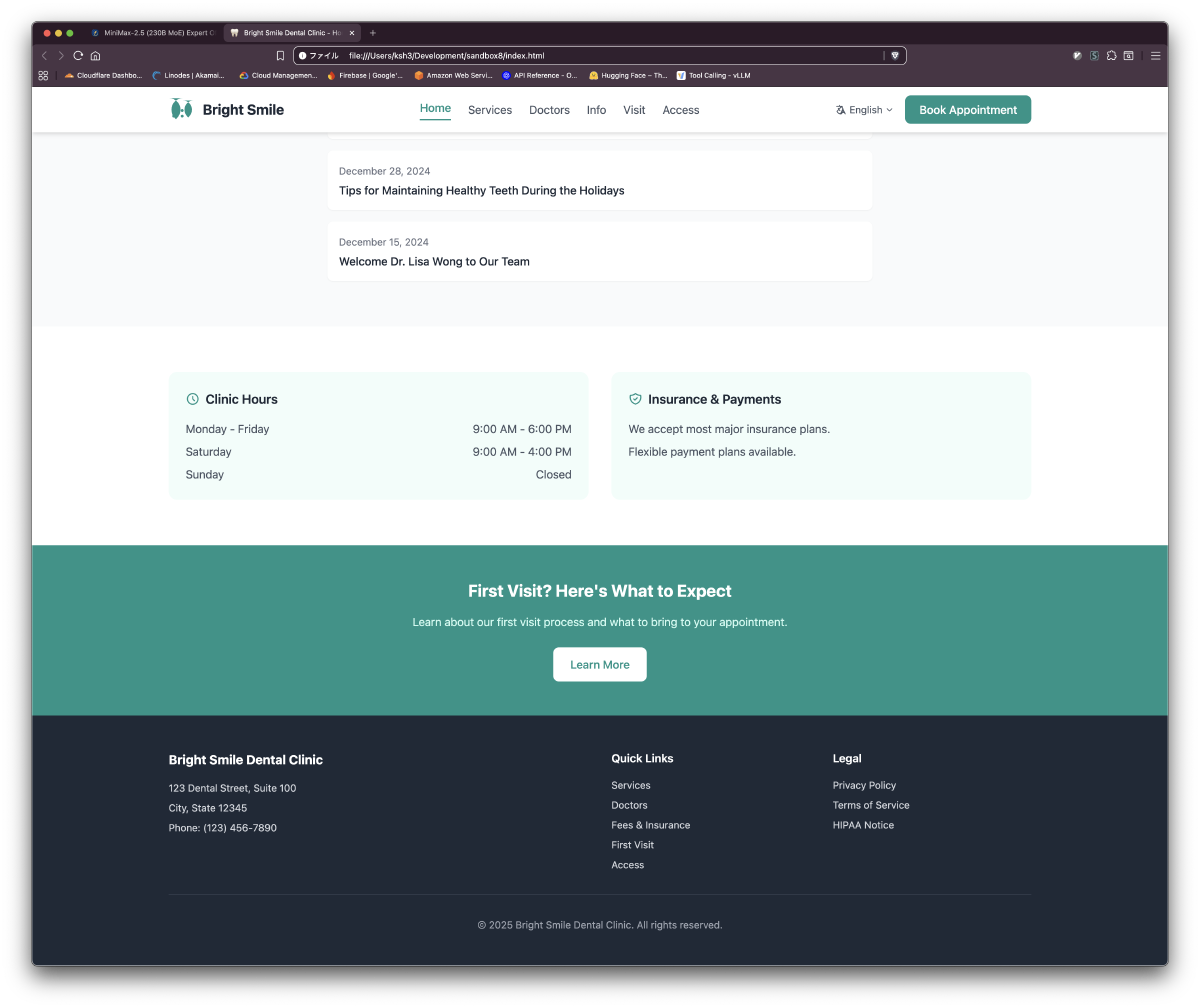
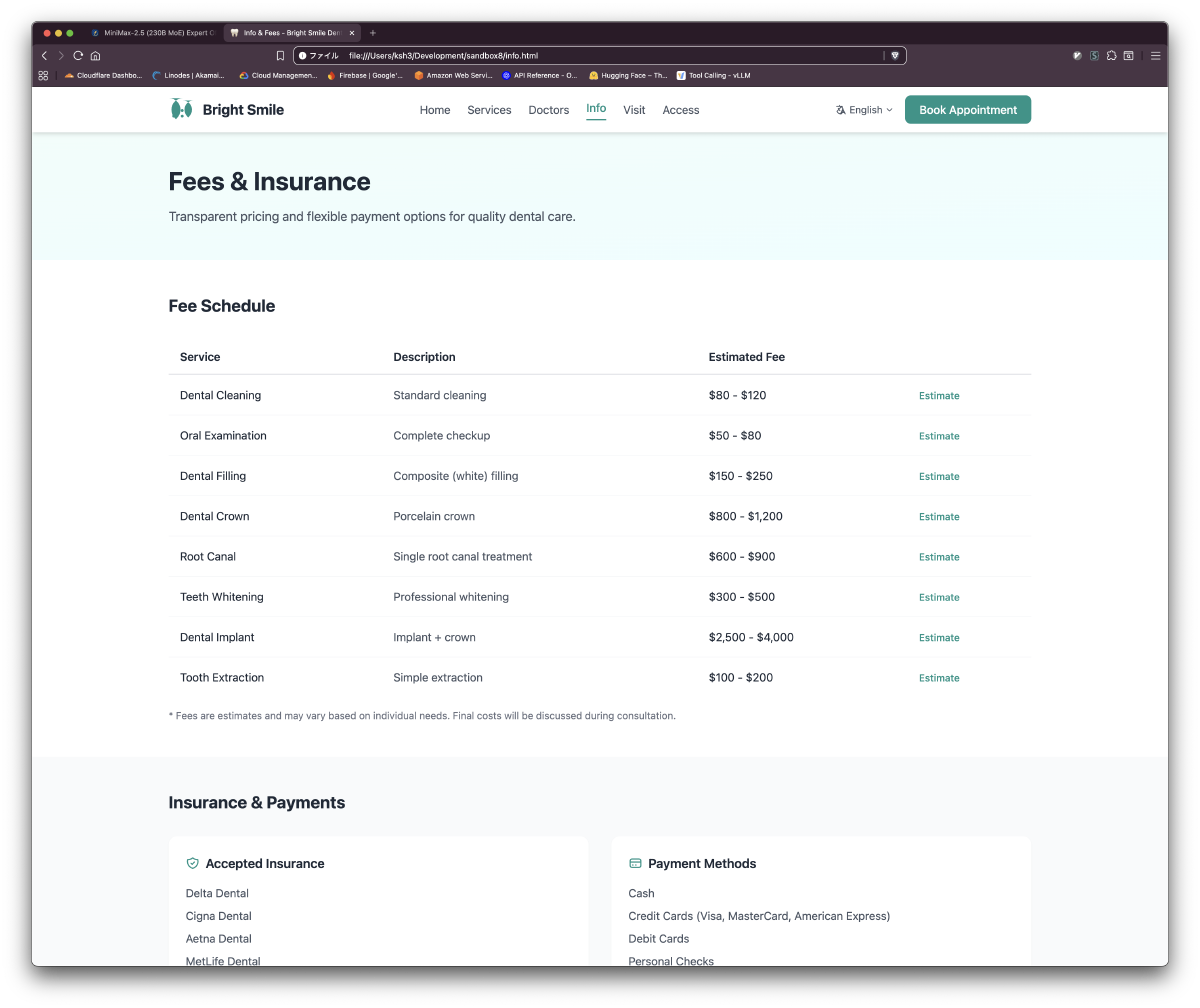
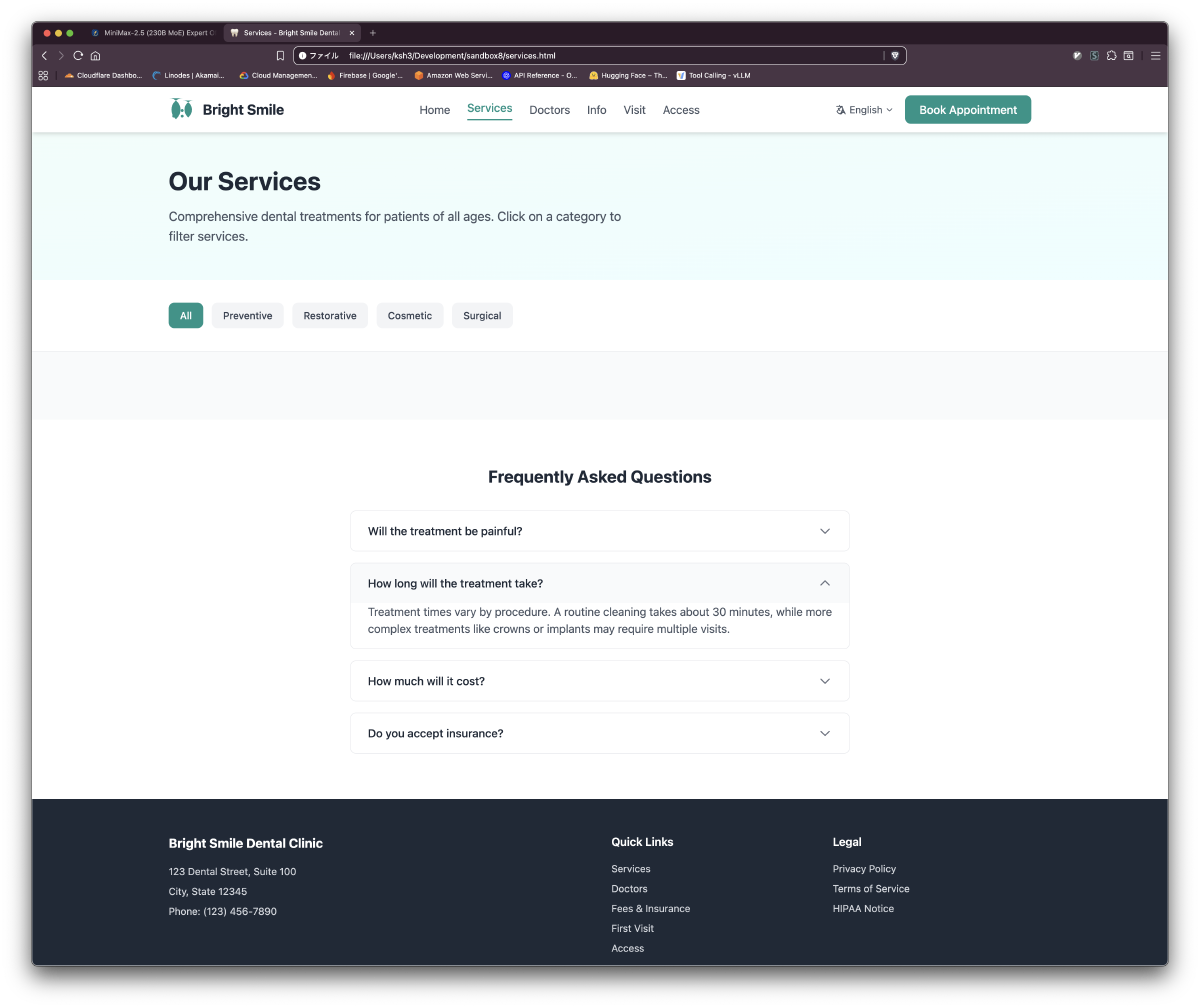
Part 3: 歯科医院静的サイト生成(IQ3_S GPU Full Load)
設計意図: なぜIQ3_Sか
IQ3_Sまで量子化を下げる目的は、Expert重みをGPU VRAMにより多く配置し、-ot exps=CPUによる遅延を抑制すること。精度は一部トレードするが、生成速度の向上がコード生成タスクでは総合的に有利と判断した。
要件
- 6ページの静的HTMLサイト(index, services, doctors, info, visit, access)
- ビルドステップなし、Tailwind CSS (CDN)、Alpine.js (CDN)
結果: 約18分で6ページ完成
| ページ | 主要コンテンツ | Alpine.jsによる動的機能 |
|---|---|---|
| index.html | ヒーロー、8サービスカード、医師プレビュー、ニュース | モバイルナビ、言語切替UI |
| services.html | 14治療カード、FAQセクション | カテゴリフィルタリング、アコーディオン |
| doctors.html | 6医師プロフィール、専門・資格 | 詳細の展開・収納 |
| info.html | 料金表、保険対応、支払い方法 | 見積もりモーダル |
| visit.html | 初診フロー、予約案内 | バリデーション付きフォーム |
| access.html | 地図、交通機関、駐車場 | 経路タブ切り替え |
- 総所要時間: 18分2秒(設計・実装・Diagnostics含む)
- 診断結果: エラー・警告なし
- 品質: IQ3_Sでもアクセシビリティ配慮(ESCキー閉鎖、フォーカス管理)、セマンティックHTML構造が維持された
生成サイトのスクリーンショット
量子化レベル別の運用指針
| 量子化 | モデルサイズ | TG速度 | 用途 |
|---|---|---|---|
| IQ5_K | 157.7 GiB | 34-37 tok/s | ベンチマーク、品質重視の生成 |
| IQ4_NL | ~120 GiB(推定) | 向上見込み | 長コンテキスト作業、React LP生成 |
| IQ3_S | ~100 GiB(推定) | さらに向上 | 構造明確な大量コード生成、速度優先タスク |
「巨大モデルを最高精度で動かす」だけが正解ではない。タスク特性に合わせて量子化を下げ、GPU Full Load寄りにして速度を優先する運用は実務で有効。
感想
229Bモデルがローカルで37 tok/sで動くこと自体が数年前には考えにくかった。Expert Offloadという「GPUに載らないならCPUに逃がす」戦略は、MoEの構造的特性(Expertが独立している)を活かした合理的なアプローチ。 React LPも歯科医院サイトも、仕様書を投げれば実用レベルのコードが出てくる。229Bクラスの判断余力は、複雑タスクでの整合性維持に確実に効いている。
再現方法
モデル取得
huggingface-cli download <quantizer>/MiniMax-M2.5-GGUF \
--include "MiniMax-M2.5-IQ5_K.gguf" \
--local-dir /mnt/data/hf/hub/models--MiniMax-2.5-GGUF
ベンチマーク実行
上記「Part 1: 実行コマンド」を参照。ik_llama.cppのExpert Offload機能が必要。
計測
curl -s http://localhost:8081/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"minimax","messages":[{"role":"user","content":"Explain MoE architecture"}],"max_tokens":512}'
補足ノウハウ
–no-mmapの必要性
157GBのモデルをmmapで読むと、ページフォールトが断続的に発生しレイテンシが不安定になる。--no-mmapで実メモリにコピーすることで推論中のページフォールトを排除できる。起動時間は数分単位で長くなる。
Expert数とDecode速度
MiniMax-2.5は256エキスパート中8個を選択する。GLM-4.7-Flash(64中4個)と比較してExpert選択の計算コストは大きいが、個々のExpertサイズは小さい(FFN 1,536次元)。Expert数だけでDecode速度は予測できない。